
This pattern and the use of replication zones are fully supported. However, for most users, they are harder to use and in some cases can result in worse performance than the multi-region SQL abstractions. Cockroach Labs recommends that you migrate to global tables whenever possible.
In a multi-region deployment, the duplicate indexes pattern is a good choice for tables with the following requirements:
- Read latency must be low, but write latency can be much higher.
- Reads must be up-to-date for business reasons or because the table is referenced by foreign keys.
- Rows in the table, and all latency-sensitive queries, cannot be tied to specific geographies.
- Table data must remain available during a region failure.
In general, this pattern is suited well for immutable/reference tables that are rarely or never updated.
See It In Action - Read about how a financial software company is using the Duplicate Indexes topology for low latency reads in their identity access management layer.
Prerequisites
Fundamentals
- Multi-region topology patterns are almost always table-specific. If you haven't already, review the full range of patterns to ensure you choose the right one for each of your tables.
- Review how data is replicated and distributed across a cluster, and how this affects performance. It is especially important to understand the concept of the "leaseholder". For a summary, see Reads and Writes in CockroachDB. For a deeper dive, see the CockroachDB Architecture documentation.
- Review the concept of locality, which makes CockroachDB aware of the location of nodes and able to intelligently place and balance data based on how you define replication controls.
- Review the recommendations and requirements in our Production Checklist.
- This topology doesn't account for hardware specifications, so be sure to follow our hardware recommendations and perform a POC to size hardware for your use case.
- Adopt relevant SQL Best Practices to ensure optimal performance.
Cluster setup
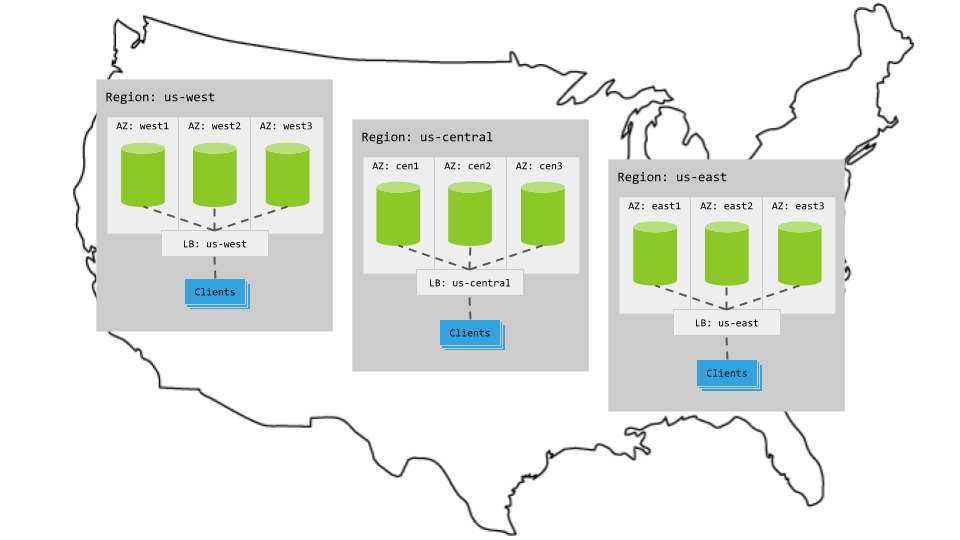
Each multi-region pattern assumes the following setup:
Hardware
- 3 regions
- Per region, 3+ AZs with 3+ VMs evenly distributed across them
- Region-specific app instances and load balancers
- Each load balancer redirects to CockroachDB nodes in its region.
- When CockroachDB nodes are unavailable in a region, the load balancer redirects to nodes in other regions.
Cluster
Each node is started with the --locality flag specifying its region and AZ combination. For example, the following command starts a node in the west1 AZ of the us-west region:
$ cockroach start \
--locality=region=us-west,zone=west1 \
--certs-dir=certs \
--advertise-addr=<node1 internal address> \
--join=<node1 internal address>:26257,<node2 internal address>:26257,<node3 internal address>:26257 \
--cache=.25 \
--max-sql-memory=.25 \
--background
Configuration
Pinning secondary indexes requires an Enterprise license.
Summary
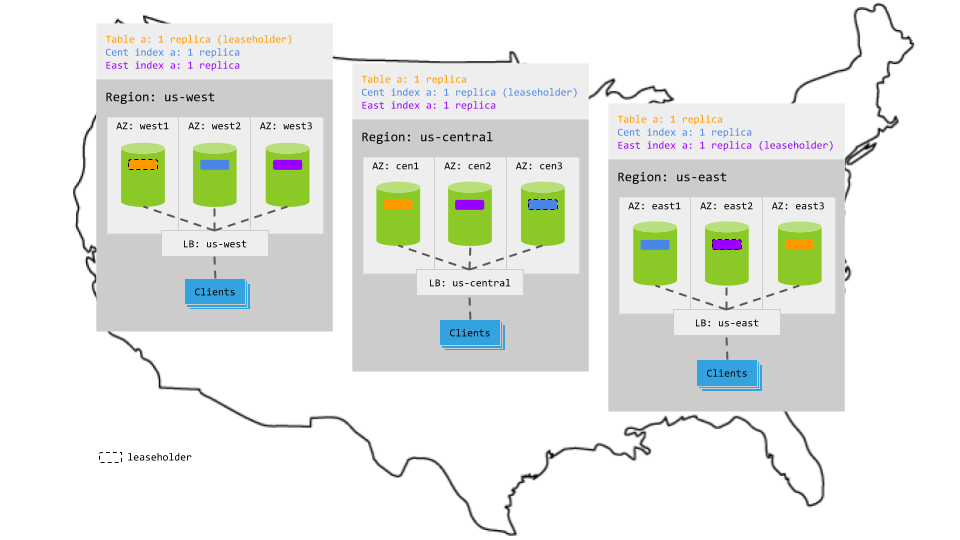
Using this pattern, you tell CockroachDB to put the leaseholder for the table itself (also called the primary index) in one region, create 2 secondary indexes on the table, and tell CockroachDB to put the leaseholder for each secondary index in one of the other regions. This means that reads will access the local leaseholder (either for the table itself or for one of the secondary indexes). Writes, however, will still leave the region to get consensus for the table and its secondary indexes.
Steps
Assuming you have a cluster deployed across three regions and a table like the following:
> CREATE TABLE postal_codes (
id INT PRIMARY KEY,
code STRING
);
If you do not already have one, request a trial Enterprise license.
Create a replication zone for the table and set a leaseholder preference telling CockroachDB to put the leaseholder for the table in one of the regions, for example
us-west:> ALTER TABLE postal_codes CONFIGURE ZONE USING num_replicas = 3, constraints = '{"+region=us-west":1}', lease_preferences = '[[+region=us-west]]';Create secondary indexes on the table for each of your other regions, including all of the columns you wish to read either in the key or in the key and a
STORINGclause:> CREATE INDEX idx_central ON postal_codes (id) STORING (code);> CREATE INDEX idx_east ON postal_codes (id) STORING (code);Create a replication zone for each secondary index, in each case setting a leaseholder preference telling CockroachDB to put the leaseholder for the index in a distinct region:
> ALTER INDEX postal_codes@idx_central CONFIGURE ZONE USING num_replicas = 3, constraints = '{"+region=us-central":1}', lease_preferences = '[[+region=us-central]]';> ALTER INDEX postal_codes@idx_east CONFIGURE ZONE USING num_replicas = 3, constraints = '{"+region=us-east":1}', lease_preferences = '[[+region=us-east]]';To confirm that replication zones are in effect, you can use the
SHOW CREATE TABLE:> SHOW CREATE TABLE postal_codes;table_name | create_statement +--------------+----------------------------------------------------------------------------+ postal_codes | CREATE TABLE postal_codes ( | id INT8 NOT NULL, | code STRING NULL, | CONSTRAINT "primary" PRIMARY KEY (id ASC), | INDEX idx_central (id ASC) STORING (code), | INDEX idx_east (id ASC) STORING (code), | FAMILY "primary" (id, code) | ); | ALTER TABLE defaultdb.public.postal_codes CONFIGURE ZONE USING | num_replicas = 3, | constraints = '{+region=us-west: 1}', | lease_preferences = '[[+region=us-west]]'; | ALTER INDEX defaultdb.public.postal_codes@idx_central CONFIGURE ZONE USING | num_replicas = 3, | constraints = '{+region=us-central: 1}', | lease_preferences = '[[+region=us-central]]'; | ALTER INDEX defaultdb.public.postal_codes@idx_east CONFIGURE ZONE USING | num_replicas = 3, | constraints = '{+region=us-east: 1}', | lease_preferences = '[[+region=us-east]]' (1 row)
Characteristics
Latency
Reads
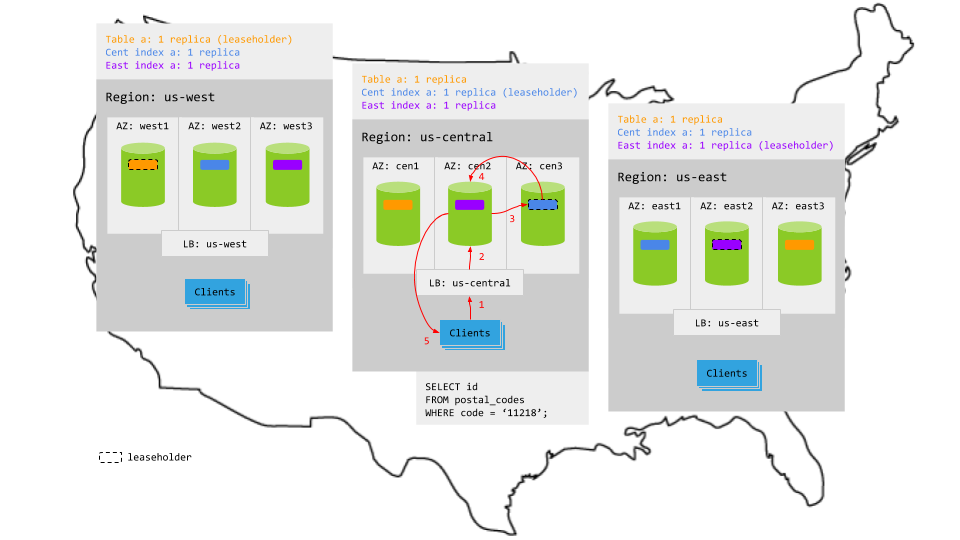
Reads access the local leaseholder and, therefore, never leave the region. This makes read latency very low.
For example, in the animation below:
- The read request in
us-centralreaches the regional load balancer. - The load balancer routes the request to a gateway node.
- The gateway node routes the request to the relevant leaseholder. In
us-west, the leaseholder is for the table itself. In the other regions, the leaseholder is for the relevant index, which the cost-based optimizer uses due to the leaseholder preferences. - The leaseholder retrieves the results and returns to the gateway node.
- The gateway node returns the results to the client.
Writes
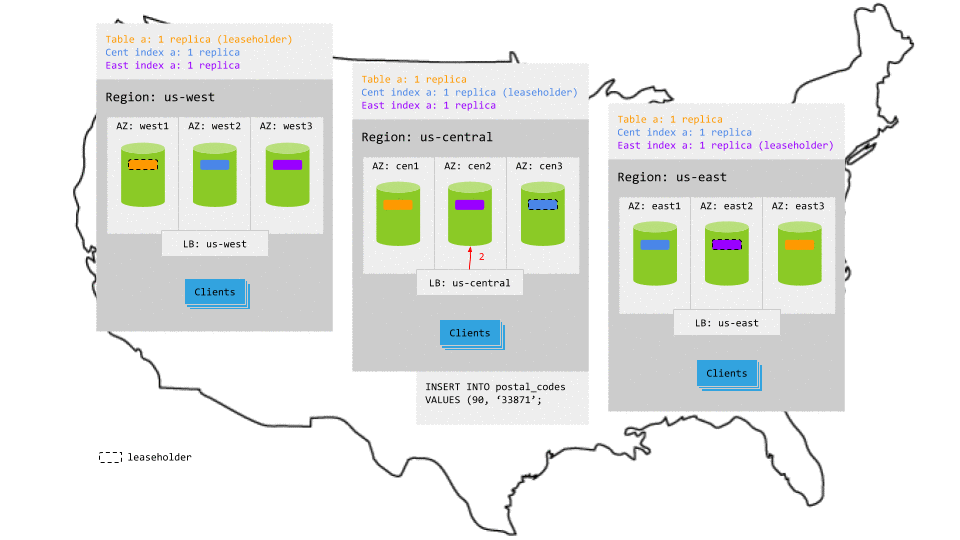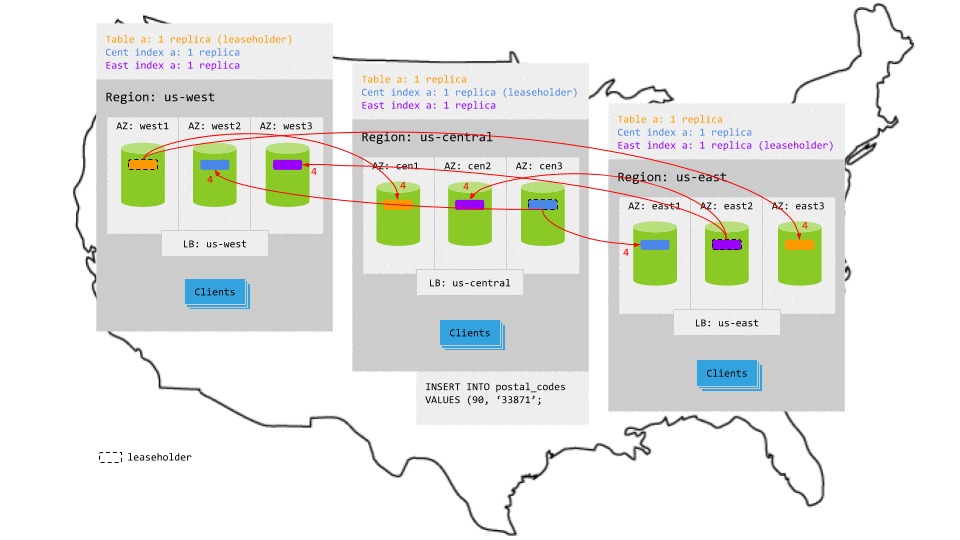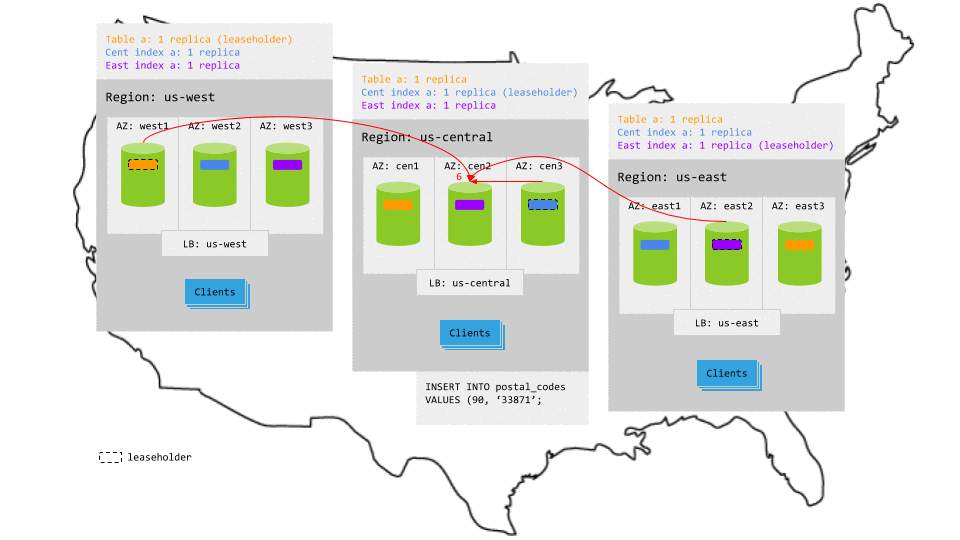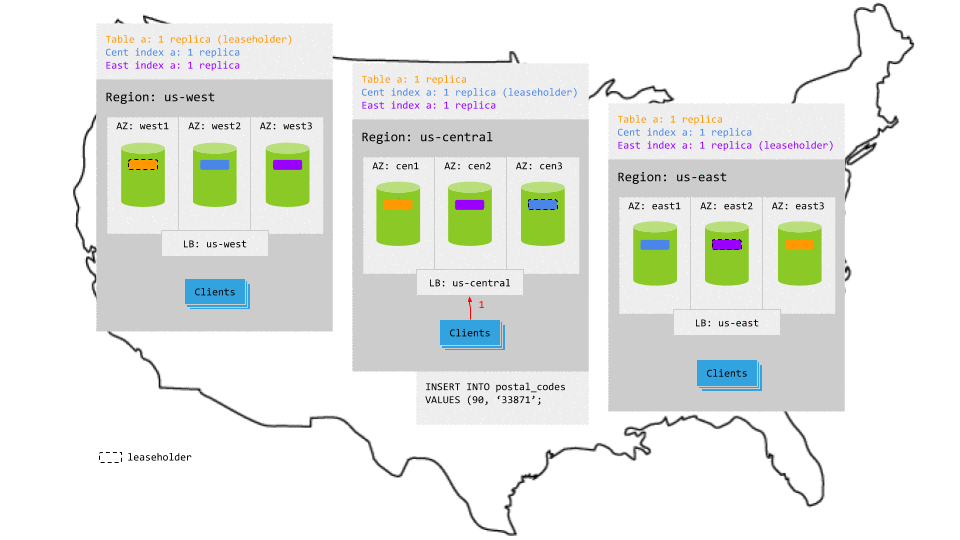
The replicas for the table and its secondary indexes are spread across all 3 regions, so writes involve multiple network hops across regions to achieve consensus. This increases write latency significantly. It's also important to understand that the replication of extra indexes can reduce throughput and increase storage cost.
For example, in the animation below:
- The write request in
us-centralreaches the regional load balancer. - The load balancer routes the request to a gateway node.
- The gateway node routes the request to the leaseholder replicas for the table and its secondary indexes.
- While each leaseholder appends the write to its Raft log, it notifies its follower replicas.
- In each case, as soon as one follower has appended the write to its Raft log (and thus a majority of replicas agree based on identical Raft logs), it notifies the leaseholder and the write is committed on the agreeing replicas.
- The leaseholders then return acknowledgement of the commit to the gateway node.
- The gateway node returns the acknowledgement to the client.
Resiliency
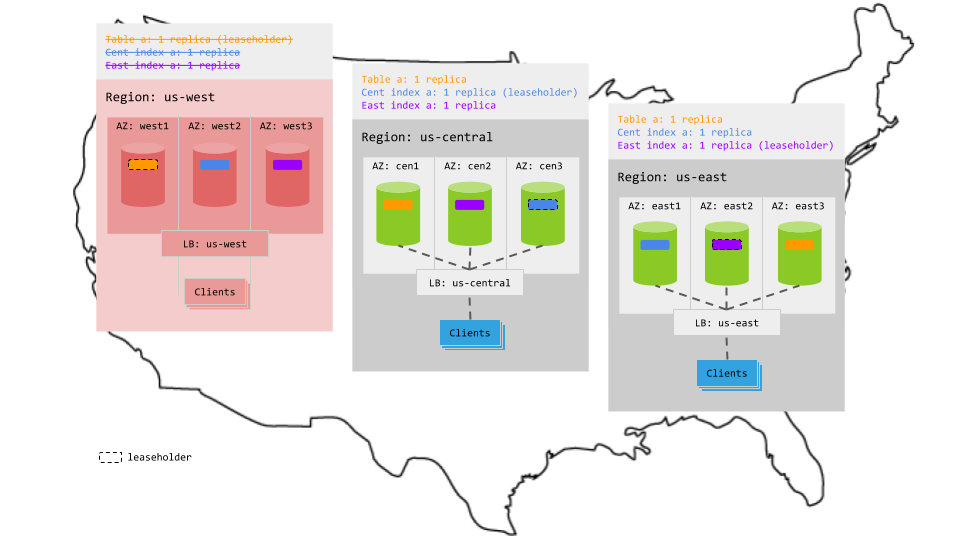
Because this pattern balances the replicas for the table and its secondary indexes across regions, one entire region can fail without interrupting access to the table:
Preferring the nearest index
Given multiple identical indexes that have different locality constraints using replication zones, the optimizer will prefer the index that is closest to the gateway node that is planning the query. In a properly configured geo-distributed cluster, this can lead to performance improvements due to improved data locality and reduced network traffic.
This feature enables scenarios such as:
- Reference data such as a table of postal codes that can be replicated to different regions, and queries will use the copy in the same region. See Example - zone constraints for more details.
- Optimizing for local reads (potentially at the expense of writes) by adding leaseholder preferences to your zone configuration. See Example - leaseholder preferences for more details.
Prerequisites
- Acquire an Enterprise license.
- Determine which data consists of reference tables that are rarely updated (such as postal codes) and can therefore be easily replicated to different regions.
- Create multiple secondary indexes on the reference tables. These indexes must include (in key or using
STORED) every column that you wish to query. For example, if you runSELECT * from db.tableand not every column ofdb.tableis in the set of secondary indexes you created, the optimizer will have no choice but to fall back to the primary index. - Create replication zones for each index.
With the above pieces in place, the optimizer will automatically choose the index nearest the gateway node that is planning the query.
The optimizer does not actually understand geographic locations, i.e., the relative closeness of the gateway node to other nodes that are located to its "east" or "west". It is matching against the node locality constraints you provided when you configured your replication zones.
Examples
Zone constraints
We can demonstrate the necessary configuration steps using a local cluster. The instructions below assume that you are already familiar with:
- How to start a local cluster.
- The syntax for assigning node locality when configuring replication zones.
- Using the built-in SQL client.
First, start 3 local nodes as shown below. Use the --locality flag to put them each in a different region as denoted by region=usa, region=eu, etc.
$ cockroach start --locality=region=usa --insecure --store=/tmp/node0 --listen-addr=localhost:26257 \
--http-port=8888 --join=localhost:26257,localhost:26258,localhost:26259 --background
$ cockroach start --locality=region=eu --insecure --store=/tmp/node1 --listen-addr=localhost:26258 \
--http-port=8889 --join=localhost:26257,localhost:26258,localhost:26259 --background
$ cockroach start --locality=region=apac --insecure --store=/tmp/node2 --listen-addr=localhost:26259 \
--http-port=8890 --join=localhost:26257,localhost:26258,localhost:26259 --background
$ cockroach init --insecure --host=localhost --port=26257
Next, from the SQL client, add your organization name and Enterprise license:
$ cockroach sql --insecure --host=localhost --port=26257
> SET CLUSTER SETTING cluster.organization = 'FooCorp - Local Testing';
> SET CLUSTER SETTING enterprise.license = 'xxxxx';
Create a test database and table. The table will have 3 indexes into the same data. Later, we'll configure the cluster to associate each of these indexes with a different datacenter using replication zones.
> CREATE DATABASE IF NOT EXISTS test;
> USE test;
CREATE TABLE postal_codes (
id INT PRIMARY KEY,
code STRING,
INDEX idx_eu (id) STORING (code),
INDEX idx_apac (id) STORING (code)
);
Next, we modify the replication zone configuration via SQL so that:
- Nodes in the USA will use the primary key index.
- Nodes in the EU will use the
postal_codes@idx_euindex (which is identical to the primary key index). - Nodes in APAC will use the
postal_codes@idx_apacindex (which is also identical to the primary key index).
ALTER TABLE postal_codes CONFIGURE ZONE USING constraints='["+region=usa"]';
ALTER INDEX postal_codes@idx_eu CONFIGURE ZONE USING constraints='["+region=eu"]';
ALTER INDEX postal_codes@idx_apac CONFIGURE ZONE USING constraints='["+region=apac"]';
To verify this feature is working as expected, we'll query the database from each of our local nodes as shown below. Each node has been configured to be in a different region, and it should now be using the index pinned to that region.
In a geo-distributed scenario with a cluster that spans multiple datacenters, it may take time for the optimizer to fetch schemas from other nodes the first time a query is planned; thereafter, the schema should be cached locally.
For example, if you have 11 nodes, you may see 11 queries with high latency due to schema cache misses. Once all nodes have cached the schema locally, the latencies will drop.
This behavior may also cause the Statements page of the Web UI to show misleadingly high latencies until schemas are cached locally.
As expected, the node in the USA region uses the primary key index.
$ cockroach sql --insecure --host=localhost --port=26257 --database=test -e 'EXPLAIN SELECT * FROM postal_codes WHERE id=1;'
tree | field | description
-------+---------------------+-----------------------
| distribution | local
| vectorized | false
scan | |
| estimated row count | 1
| table | postal_codes@primary
| spans | [/1 - /1]
(6 rows)
As expected, the node in the EU uses the idx_eu index.
$ cockroach sql --insecure --host=localhost --port=26258 --database=test -e 'EXPLAIN SELECT * FROM postal_codes WHERE id=1;'
tree | field | description
-------+---------------------+----------------------
| distribution | local
| vectorized | false
scan | |
| estimated row count | 1
| table | postal_codes@idx_eu
| spans | [/1 - /1]
(6 rows)
As expected, the node in APAC uses the idx_apac index.
$ cockroach sql --insecure --host=localhost --port=26259 --database=test -e 'EXPLAIN SELECT * FROM postal_codes WHERE id=1;'
tree | field | description
-------+---------------------+------------------------
| distribution | local
| vectorized | false
scan | |
| estimated row count | 1
| table | postal_codes@idx_apac
| spans | [/1 - /1]
(6 rows)
You'll need to make changes to the above configuration to reflect your production environment, but the concepts will be the same.
Leaseholder preferences
If you provide leaseholder preferences in addition to replication zone constraints, the optimizer will attempt to take your leaseholder preferences into account as well when selecting an index for your query. There are several factors to keep in mind:
Zone constraints are always respected (hard constraint), whereas lease preferences are taken into account as "additional information" -- as long as they do not contradict the zone constraints.
The optimizer does not consider the real-time location of leaseholders when selecting an index; it is pattern matching on the text values passed in the configuration (e.g., the
ALTER INDEXstatements shown below). For the same reason, the optimizer only matches against the first locality in yourlease_preferencesarray.The optimizer may use an index that satisfies your leaseholder preferences even though that index has moved to a different node/region due to leaseholder rebalancing. This can cause slower performance than you expected. Therefore, you should only use this feature if you’re confident you know where the leaseholders will end up based on your cluster's usage patterns. We recommend thoroughly testing your configuration to ensure the optimizer is selecting the index(es) you expect.
In this example, we'll set up an authentication service using the access token / refresh token pattern from OAuth 2. To support fast local reads in our geo-distributed use case, we will have 3 indexes into the same authentication data: one for each region of our cluster. We configure each index using zone configurations and lease preferences so that the optimizer will use the local index for better performance.
The instructions below assume that you are already familiar with:
- How to start a local cluster.
- The syntax for assigning node locality when configuring replication zones.
- Using the built-in SQL client.
First, start 3 local nodes as shown below. Use the --locality flag to put them each in a different region.
$ cockroach start --locality=region=us-east --insecure --store=/tmp/node0 --listen-addr=localhost:26257 \
--http-port=8888 --join=localhost:26257,localhost:26258,localhost:26259 --background
$ cockroach start --locality=region=us-central --insecure --store=/tmp/node1 --listen-addr=localhost:26258 \
--http-port=8889 --join=localhost:26257,localhost:26258,localhost:26259 --background
$ cockroach start --locality=region=us-west --insecure --store=/tmp/node2 --listen-addr=localhost:26259 \
--http-port=8890 --join=localhost:26257,localhost:26258,localhost:26259 --background
$ cockroach init --insecure --host=localhost --port=26257
From the SQL client, add your organization name and Enterprise license:
$ cockroach sql --insecure --host=localhost --port=26257
> SET CLUSTER SETTING cluster.organization = 'FooCorp - Local Testing';
> SET CLUSTER SETTING enterprise.license = 'xxxxx';
Create an authentication database and table:
> CREATE DATABASE if NOT EXISTS auth;
> USE auth;
> CREATE TABLE token (
token_id VARCHAR(100) NULL,
access_token VARCHAR(4000) NULL,
refresh_token VARCHAR(4000) NULL
);
Create the indexes for each region:
> CREATE INDEX token_id_west_idx ON token (token_id) STORING (access_token, refresh_token);
> CREATE INDEX token_id_central_idx ON token (token_id) STORING (access_token, refresh_token);
> CREATE INDEX token_id_east_idx ON token (token_id) STORING (access_token, refresh_token);
Enter zone configurations to distribute replicas across the cluster as follows:
- For the "East" index, store 2 replicas in the East, 2 in Central, and 1 in the West. Further, prefer that the leaseholders for that index live in the East or, failing that, in the Central region.
- Follow the same replica and leaseholder patterns for each of the Central and West regions.
The idea is that, for example, token_id_east_idx will have sufficient replicas (2/5) so that even if one replica goes down, the leaseholder will stay in the East region. That way, if a query comes in that accesses the columns covered by that index from the East gateway node, the optimizer will select token_id_east_idx for fast reads.
The ALTER TABLE statement below is not required since it's later made redundant by the token_id_west_idx index. In production, you might go with the ALTER TABLE to put your table's lease preferences in the West, and then create only 2 indexes (for East and Central); however, the use of 3 indexes makes the example easier to understand.
> ALTER TABLE token CONFIGURE ZONE USING
num_replicas = 5, constraints = '{+region=us-east: 1, +region=us-central: 2, +region=us-west: 2}', lease_preferences = '[[+region=us-west], [+region=us-central]]';
> ALTER INDEX token_id_east_idx CONFIGURE ZONE USING num_replicas = 5,
constraints = '{+region=us-east: 2, +region=us-central: 2, +region=us-west: 1}', lease_preferences = '[[+region=us-east], [+region=us-central]]';
> ALTER INDEX token_id_central_idx CONFIGURE ZONE USING num_replicas = 5,
constraints = '{+region=us-east: 2, +region=us-central: 2, +region=us-west: 1}', lease_preferences = '[[+region=us-central], [+region=us-east]]';
> ALTER INDEX token_id_west_idx CONFIGURE ZONE USING num_replicas = 5,
constraints = '{+region=us-west: 2, +region=us-central: 2, +region=us-east: 1}', lease_preferences = '[[+region=us-west], [+region=us-central]]';
Next let's check our zone configurations to make sure they match our expectation:
> SHOW ZONE CONFIGURATIONS;
The output should include the following:
target | raw_config_sql
---------------------------------------------------+---------------------------------------------------------------------------------------
RANGE default | ALTER RANGE default CONFIGURE ZONE USING
| range_min_bytes = 134217728,
| range_max_bytes = 536870912,
| gc.ttlseconds = 90000,
| num_replicas = 3,
| constraints = '[]',
| lease_preferences = '[]'
DATABASE system | ALTER DATABASE system CONFIGURE ZONE USING
| range_min_bytes = 134217728,
| range_max_bytes = 536870912,
| gc.ttlseconds = 90000,
| num_replicas = 5,
| constraints = '[]',
| lease_preferences = '[]'
RANGE meta | ALTER RANGE meta CONFIGURE ZONE USING
| range_min_bytes = 134217728,
| range_max_bytes = 536870912,
| gc.ttlseconds = 3600,
| num_replicas = 5,
| constraints = '[]',
| lease_preferences = '[]'
RANGE system | ALTER RANGE system CONFIGURE ZONE USING
| range_min_bytes = 134217728,
| range_max_bytes = 536870912,
| gc.ttlseconds = 90000,
| num_replicas = 5,
| constraints = '[]',
| lease_preferences = '[]'
RANGE liveness | ALTER RANGE liveness CONFIGURE ZONE USING
| range_min_bytes = 134217728,
| range_max_bytes = 536870912,
| gc.ttlseconds = 600,
| num_replicas = 5,
| constraints = '[]',
| lease_preferences = '[]'
TABLE system.public.replication_constraint_stats | ALTER TABLE system.public.replication_constraint_stats CONFIGURE ZONE USING
| gc.ttlseconds = 600,
| constraints = '[]',
| lease_preferences = '[]'
TABLE system.public.replication_stats | ALTER TABLE system.public.replication_stats CONFIGURE ZONE USING
| gc.ttlseconds = 600,
| constraints = '[]',
| lease_preferences = '[]'
TABLE auth.public.token | ALTER TABLE auth.public.token CONFIGURE ZONE USING
| num_replicas = 5,
| constraints = '{+region=us-central: 2, +region=us-east: 1, +region=us-west: 2}',
| lease_preferences = '[[+region=us-west], [+region=us-central]]'
INDEX auth.public.token@token_id_east_idx | ALTER INDEX auth.public.token@token_id_east_idx CONFIGURE ZONE USING
| num_replicas = 5,
| constraints = '{+region=us-central: 2, +region=us-east: 2, +region=us-west: 1}',
| lease_preferences = '[[+region=us-east], [+region=us-central]]'
INDEX auth.public.token@token_id_central_idx | ALTER INDEX auth.public.token@token_id_central_idx CONFIGURE ZONE USING
| num_replicas = 5,
| constraints = '{+region=us-central: 2, +region=us-east: 2, +region=us-west: 1}',
| lease_preferences = '[[+region=us-central], [+region=us-east]]'
INDEX auth.public.token@token_id_west_idx | ALTER INDEX auth.public.token@token_id_west_idx CONFIGURE ZONE USING
| num_replicas = 5,
| constraints = '{+region=us-central: 2, +region=us-east: 1, +region=us-west: 2}',
| lease_preferences = '[[+region=us-west], [+region=us-central]]'
(11 rows)
Now that we've set up our indexes the way we want them, we need to insert some data. The first statement below inserts 10,000 rows of placeholder data; the second inserts a row with a specific UUID string that we'll later query against to check which index is used.
On a freshly created cluster like this one, you may need to wait a moment after adding the data to give automatic statistics time to update. Then, the optimizer can generate a query plan that uses the expected index.
> INSERT
INTO
token (token_id, access_token, refresh_token)
SELECT
gen_random_uuid()::STRING,
gen_random_uuid()::STRING,
gen_random_uuid()::STRING
FROM
generate_series(1, 10000);
> INSERT
INTO
token (token_id, access_token, refresh_token)
VALUES
(
'2E1B5BFE-6152-11E9-B9FD-A7E0F13211D9',
'49E36152-6152-11E9-8CDC-3682F23211D9',
'4E0E91B6-6152-11E9-BAC1-3782F23211D9'
);
Finally, we EXPLAIN a selection query from each node to verify which index is being queried against. For example, when running the query shown below against the us-west node, we expect it to use the token_id_west_idx index.
$ cockroach sql --insecure --host=localhost --port=26259 --database=auth # "West" node
> EXPLAIN
SELECT
access_token, refresh_token
FROM
token
WHERE
token_id = '2E1B5BFE-6152-11E9-B9FD-A7E0F13211D9';
tree | field | description
-------+---------------------+--------------------------------------------------------------------------------------
| distribution | local
| vectorized | false
scan | |
| estimated row count | 1
| table | token@token_id_east_idx
| spans | [/'2E1B5BFE-6152-11E9-B9FD-A7E0F13211D9' - /'2E1B5BFE-6152-11E9-B9FD-A7E0F13211D9']
(6 rows)
Similarly, queries from the us-east node should use the token_id_east_idx index (and the same should be true for us-central).
$ cockroach sql --insecure --host=localhost --port=26257 --database=auth # "East" node
> EXPLAIN
SELECT
access_token, refresh_token
FROM
token
WHERE
token_id = '2E1B5BFE-6152-11E9-B9FD-A7E0F13211D9';
tree | field | description
-------+---------------------+--------------------------------------------------------------------------------------
| distribution | local
| vectorized | false
scan | |
| estimated row count | 1
| table | token@token_id_east_idx
| spans | [/'2E1B5BFE-6152-11E9-B9FD-A7E0F13211D9' - /'2E1B5BFE-6152-11E9-B9FD-A7E0F13211D9']
(6 rows)
You'll need to make changes to the above configuration to reflect your production environment, but the concepts will be the same.
Alternatives
- If reads from a table can be historical (4.8 seconds or more in the past), consider the Follower Reads pattern.
- If rows in the table, and all latency-sensitive queries, can be tied to specific geographies, consider the Geo-Partitioned Leaseholders pattern. Both patterns avoid extra secondary indexes, which increase data replication and, therefore, higher throughput and less storage.
Tutorial
For a step-by-step demonstration of how this pattern gets you low-latency reads in a broadly distributed cluster, see the Low Latency Multi-Region Deployment tutorial.
See also
- Multi-Region Capabilities Overview
- Choosing a multi-region configuration
- When to use
ZONEvs.REGIONsurvival goals - When to use
REGIONALvs.GLOBALtables - Multi-region SQL performance
- Migrate to Multi-region SQL
ALTER DATABASE ... SURVIVE {ZONE,REGION} FAILUREALTER TABLE ... SET LOCALITY ...- Topology Patterns Overview
- Single-region
- Multi-region
Was this helpful?